
MicronicsはFormlabsに買収されたよ。
出来立てのベンチャーが作った安価な製品初号機が良いか、SLSにもある程度の経験のある大企業が関わった高価な製品が良いか。
Formlabsは既存のSLSプリンタ(Fuseシリーズ)があるから、Micronicsのプリンタを売るかどうかがまず問題になるけど、売らないとなるとDIYerからのバッシングが強いだろうしなー。とはいえ、Formlabsはコンシューマー向けからは手を引いてる印象だからDIYerが怒ったところで痛くも痒くもないだろうし。Fuseを買うほど体力のない会社向けに低価格機としてMicornics系を出す可能性はあるにしても、せいぜい数倍程度のスケールだとラインナップ的にそこまで魅力があるかというと怪しい気もする。周辺機器(後処理の機材)はFuseと共通化させるだろうから結局トータルコストで見ると大して変わらない程度の価格差になるだろうし。
素人考えだと、エネルギー保存則がどうにもならない以上は水を電気分解して(貯蔵せずに)直接燃焼させるなら、電気エネルギーをどうにかしたほうが効率いいんじゃないか、という気はするけども。
しかし金属積層造形を外注してホットガススラスタの燃焼室を個人が作れるような時代になったってのは面白いな。
パリ五輪、試験運航予定の「空飛ぶタクシー」に市が直前抗議 「金持ち専用、環境に悪い」 - 産経ニュース
新しいテクノロジーってのはたいてい金持ち向けの高級品から始まって、そのうち安くなって広く普及する、ってパターンだと思うんだけどねぇ。これに限らず、うまく発展させることができれば数年後とか数十年後とかに普及したであろう面白いもの・便利なものを、芽のうちに金持ち向けだとかの異論で(あるいはもっと直接的にコストの問題で)摘まれるのが不景気の嫌なところ。
自動車も蒸気船も飛行機も、動力を使うモビリティはかなりの数がフランスで生まれたんだから、フランス人はモビリティにもっと自信を持てばいいのにな。欧州は環境問題の声が大きいからこれからの時代は難しそうよなぁ。

https://www.amazon.co.jp/dp/B0D4V5VPSL/
どちらかといえばSFというよりは普通のラノベに近い感じ。だいぶスッキリとした後味。杞憂しようと思えばいくらでもできるけど。理工系の雰囲気のラノベを読みたいなら表紙買いしても問題ないはず。しっかりしたハードSFみたいな内容ではないけど。
https://www.hitachihyoron.com/jp/pdf/1974/05/1974_05_03.pdf
日立の、テレビ中継用の電源。商用電源が敷設できないような場所での使用を想定して、ヒドラジンと空気を反応させる燃料電池。50W程度の電源で、放送用機器には34Wを供給する。放送電力は数Wとかの程度のはずだから、かなり小規模な中継局向け。500Lのヒドラジンで半年程度持つらしい。
ポータブルの発電機くらいの大きさでも定格出力は1kW程度あるから、50W程度の消費電力だと相当小型のものを作る必要があって、燃焼機関の発電機では過剰になりそうだし、特にレシプロみたいに可動部が多かったりダイナミックバランスが悪かったりすると信頼性の問題が出てくる。燃料電池は可動部がかなり少ない(制御用の弁とか液体を動かすためのポンプ類とかだけでいい)から、信頼性が向上できる。
ただ、昨今のレベルA化学防護服みたいなのを着用して衛星のヒドラジンの充填とか漏洩検査とかやってるのを見ると、そんなところでヒドラジン使うのかよ、という感じ。まあ、半世紀も前の話だしな。労働衛生も今とは全く別物だろうし。。。/* ISASが宇宙機で最初にヒドラジンを積んだのがMS-T5あたりのはずだから、それよりも10年くらい前の話 */
ボーイングのB787の開発が遅れたのはB777から間が空きすぎたから、みたいな話があったけど、B787の次世代機ってどうなってるんかなー。737とか777の改良でお茶を濁しているけど、新規開発の経験が20年とか開くとノウハウとか綺麗さっぱり失われそう。エアバスがA380でちょっと遅れた間にボーイングが787の次世代機で引き離していればよかったものを、A350で巻き返されたあげく今のボーイングは見る影もないからなぁ。
日本の次の小型旅客機がある程度成功すれば日米共同で大型旅客機を開発するみたいな可能性も……とは思いつつ色々絵に描いた餅。
***
久しぶりにマイクラで遊んでる。
鉄トラップってどんなものなんだろ、と思ってググって出てきたやつをクリエイティブモードで作っても、動かねーの。しょうがないので、fandomのアイアンゴーレムの記事を参考にゴーレムの出現条件を満たせそうなトラップの構造を考えてみた。
とりあえず動く形は得られた。ただ、結構大量に村人を配置した割に、いまいち効率が良くない。
別の構造

そこそこいい感じの効率が得られている感じ。

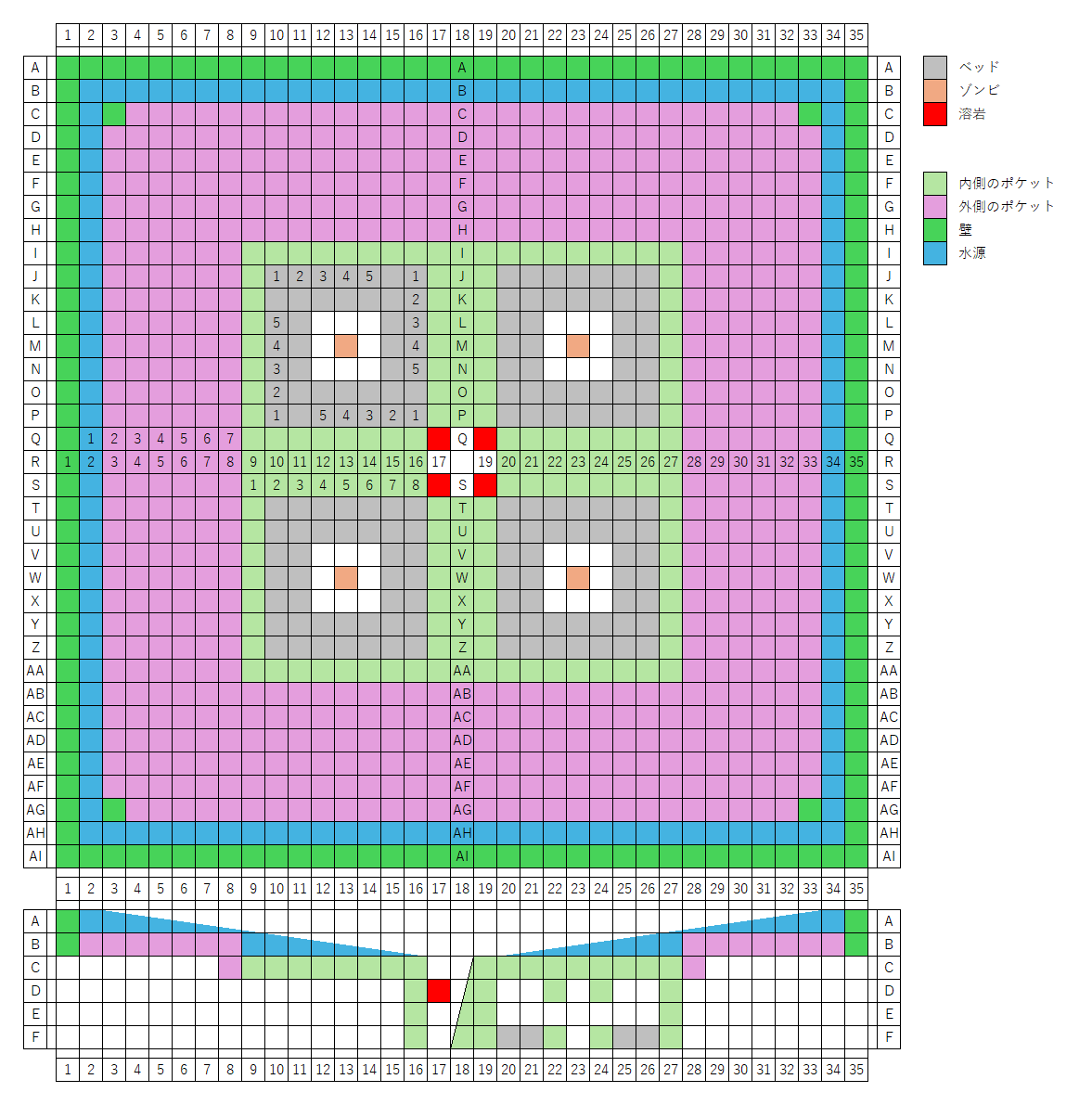
内側が7x7(高さ3)の部屋を1セルとして、それを4個並べて、中央に3x3の炉を作る。
セルの中央にポケットを作ってゾンビを配置する。

村人とゾンビが接触すると村人が感染するので、3x3の土を床と天井の2箇所に配置して、その隙間から村人にゾンビのタゲが向くようにする。ゾンビには名札が必要。セルあたりベッドが20個あるので、トータルで80人の村人が配置されている。
セルの天井を貼って、内側に19x19のポケットを、その1段上に33x33のポケットを作る。ポケットの外周に壁を作って、そこに水を撒く(内側全体が無限水源にならないように注意)。
今回はクリエイティブモード(スーパーフラット)だから地上にfillコマンドで作ったけど、下に向かって彫り込んでいくほうが楽に作れる。

炉にはマグマが4個、看板で浮かせてあって、その下にホッパーを配置して、適当な場所にチェストを置いておく。炉に通じる1箇所に窓を作っておけばアイアンゴーレムが落ちてきたときに燃えるのが窓から見えるから、「炉」っぽさが出る。
炉の大きさが2x2だと複数のゴーレムが落ちてきたときに互いを押し合って炉に落ちてこないので、3x3の穴が良い。
図
cloneして村人を5人/cellと20人/cellで比較

ある程度の時間動かして比較すると有意に差があるけど、とはいえ4倍までは行かない。せいぜい数割程度かな。
***
試しにOpenCvSharpでQRコードの検出。
Level1(21x21)で複数の大きさを誤り訂正レベルごとに表示した画像を印刷して検出。

下がOpenCvSharpでデコードした結果。意外と性能悪い。
ちなみに、画像を4倍に拡大して処理するとこんな感じ

さっきは検出できなかった場所も検出できているし、さっきは検出できていた場所が検出できなくなっている。
OpenCVのQRCodeDetectorはQRコードの画素サイズをある程度決め打ちして、その範囲内にあるものだけ検出する、みたいなロジックらしい。
ZXing.Netでもテスト

OpenCVよりだいぶ優秀。上から2段目の左から1個目が認識されていないのが謎い。これだけデカいんだから認識しても良さそうなのに。小さい方はQだけ7.543も認識できているけど、これはエラー訂正率とかの問題ではなく、単にQだけピクセルがきれいに見えているみたいなことだと思う。
マーカーを横方向に30個くらい並べたやつを認識して遊んだら面白そうだなーと思ってちょろっと2次元コードを触っている次第。
マーカーは2^11くらいを識別できれば十分なので、QRコードLevel1H(10^17≒2^56)は明らかに情報量が多すぎる。
例えばDataMatrixは最小10x10ドットで10^6(≒2^20)を識別できる。ただ、DataMatrixのデコーダはZXingにしろML Kitみたいな機械学習ベースのライブラリにしろ、画像中央にDataMatrixが配置されているのが前提らしくて、1画像内に複数のコードがあってもデコードできないらしい(ブルートフォース的に切り出して処理する手はあるし、画像処理で直線(ファインダ)を探して周辺を切り出す、みたいな方法は考えられるにしても)。
Aztec(アステカ)Codeだと、最小15x15ドットで数字なら15文字(10^15≒2^50)まで詰め込めるらしい。
Aztecは中央にマーカー(アステカ文明の多段ピラミッドのような形)が配置されているので、QRコードと同様に任意の場所にあるマーカーを認識できるのが利点。ただ、ZXingの場合は画像中央に水平に配置されたAztecしか認識できないっぽい。少しでも傾いたり、位置がずれたりすると、認識できない。DataMatrixは45度付近が認識できないけど、Aztecはそれより遥かに厳しい。
MaxiCodeも中央付近・水平近くしかデコードできないかな? あと、ZXingはMaxiCodeReaderがあるけど、エンコード(Writer)がよくわからない。普通にエンコードしようとするとNo encoder available for format MAXICODE例外が出る。MaxiCodeは離散値の直交座標では表現できないから、既存のZXingの中間形式だと取り扱えないはずだし。
結局のところ、ZXingの2DコードデコーダはQRコードを除いて画像中央に配置されたコードしか認識できず、DataMatrix以外は読み取り可能な角度に厳しい制限がある。DataMatrixは画像中央に配置されている限りは比較的ロバスト(完全なひし形は読めない)。QRコードは画像中央に配置する必要がなく、複数のコードを同時に読み取ることができる。
OpenCVのQRCodeDetectorのDetectメソッドは「かなりQRコードっぽいやつ」を認識してくれるので、切り出しマーカー3個とチェッカーボードがあれば「QRコードっぽいぞ!」と検出してくれる(切り出しマーカーだけだと無理)。
なので、たとえば

みたいな図形を用意してやれば、青色だけ見ればQRコード風マーカーに、赤色だけ見ればDataMatrixに、という風に認識できる。一旦OpenCVでQRコードを探して、その場所を切り出してからZXingに渡してDataMatrixとしてデコードする、みたいなロジックもできるはず。結構手間がかかるのが難点。
他の方法としては

みたいにDataMatrixを切り出しマーカーで囲う方法もある。ただしDataMatrixの内容によってはOpenCVで検出できない可能性や、面積が大幅に増える欠点がある。
ただ、色で多重化するにしろ、空間で多重化するにしろ、結局はOpenCVのQRコード検出器の機嫌次第なので、最初からOpenCVのDecoderを使えばいいじゃん、みたいな話に返ってくる。で、認識できる大きさに制限がついてくる。
もうちょっと手間のかかる方法だと、DataMatrixと円を色多重化しておいて、OpenCVで円形を検出して、その位置と大きさからDataMatrixの範囲を推定して、そこを切り出してZXingに渡す、みたいな処理も考えられる。この方法だとOpenCVのQR.Detectorに依存せずにDataMatrixを検出できる。
ついでなので、ArUcoもテスト

↑7x7_1000 / ↓4x4_1000

画像認識専用に作ったマーカーだから当たり前とはいえ、かなり優秀。
事前定義の辞書ではマーカーが1000個までしかないから、大量のマーカーが必要な場合は拡張性に若干の懸念がある。マーカーを複数個連結して組み合わせを増やす例もあるらしいけど、方法は不明(後処理でマーカーの距離を見て組み合わせを探すのかな?)。あるいはカスタム辞書を作成する方法もあるらしい。ただ、OpenCvSharpではカスタム辞書関係は未実装っぽい感じ?
画素数の違うArUcoマカーは分離できるっぽいので、4x4_1000から7x7_1000まで使えば4000個のマーカーが得られるから、場所に応じて大きく表示できる場所には7x7を、面積が取れない場所には4x4を、みたいな感じで使うことはできるかもしれない。何回も画像認識処理を呼ぶコストはかかるけど、最大で約2^12くらいのマーカーを作れる。
ドキュメントだと例えば4x4_50と4x4_1000では50のほうがハミング距離が長く取ってあるから、必要なマーカーが少ない場合はできるだけ小さい辞書を使うべきらしい。とはいえ、4x4_50は4x4_1000の最初の50個が入っているだけだから、_50を使おうと_1000を使おうと関係ない気がする(強いて言うなら乱雑に使ったり後ろの方から使うのはやめろ、とか)。
OpenCvSharpでもCvAruco.ReadDictionaryは用意されているので、ファイルから辞書を読み込むことはできる。辞書ファイルはテキストベースでビットマップを保存している感じらしい。例えば以下のような感じ。
これで3x3のマーカーを1個持った辞書を読み込める。maxCorrectionBitsというのは何個までのビットエラーを許容するか、みたいなパラメータらしい(もうちょっと複雑かも)。
辞書をファイルで持てるので、事前定義された範囲外のマーカー(3x3とか8x8以上)であったり、大量(数千個)のマーカーを持つことができる。ただしマーカー間で誤検出しないように十分なハミング距離を持っていることを自分で保証する必要がある(あるいは誤検知を許容できる用途で使うか)。
簡易的な方法でやるなら、マーカーをulongで保持してxorすればpopcountでハミング距離が得られるから、乱数でマーカーを作って誤認しづらいマーカーだけ保存する、みたいなロジックが作れる(回転対称のビット並べ替え処理が必要)。そもそも画像処理でビット反転ってどういうことだよっていう気がしないでもないけど。どちらかといえばクロストーク(サンプリング位置ズレ)とかのほうが影響は大きそうな気もする。
ある程度大きなマーカー(小さい画素)を許容できるのであれば、DataMatrixを10x10のマーカーとして使うこともできる(マーカーが大きくなると処理コストが増えるらしいけど)。

DataMatrixとしての可読性を求めないのであればアライメントやクロックを削除して8x8として作れる(回転対称のパターンが出る可能性が出てきそうだけど)。
試しにDataMatrixで0から1023までを、アライメントを削除して9x9のマーカー化

連番が途中に入るので隣接したマーカーはハミング距離が小さくなりそう(マーカー全体で見るとRS符号があるのである程度の距離は確保できているはずだけど)。
やはりArUcoはアルゴリズム的に作るのではなくて、ブルートフォース的にやるべきなんだろうな。
OpenCvSharpにも辞書内のマーカーとの距離を求めるメソッドは提供されているけど、計測するデータをMatで渡さなきゃいけないのでC#から扱うのは面倒くさそう。そもそもOpenCvSharpの辞書は追記ができないから、距離を測ったところで大して意味はないし(1個マーカーを追加するたびにファイルから辞書を読み直す、みたいなことをやる必要が出てくる)。
それっぽい辞書ファイルを作成することはできるけど、実用的な辞書ファイルを作成するなら色々工夫が必要になりそう。
とりあえず今回のところは、OpenCvで姿勢推定をやりたいならArUcoをつかえ(あたりまえ)、ArUcoの辞書はプリセットでもたぶん十分(1000個もある)、OpenCvSharpでもオリジナルの辞書は作成できる(手間はかかる)、あたりの教訓が得られた。
0 件のコメント:
コメントを投稿